table of content
说明
测试环境
使用LLaMA Factory (daa318535097a51bdb8546960a9e4b4681c11dfe)训练,除了fp16之外尽量采用了默认配置。
训练模型为qwen/Qwen-1_8B,数据集为belle_math(因为看着最小)
根据占用判断,cpu应该不是瓶颈所在
- 2080ti 改22G, EPYC 7551p, esxi内的ubuntu虚拟机
- 4090, EPYC 7713, docker内
- 4090-2, EPYC 7713, docker内
- v100 16GB显存 8核CPU 40GB内存, openbayes
- a6000 48GB显存 16核CPU 60GB内存, openbayes
- a6000-2 96GB显存 32核CPU 120GB内存, openbayes
- a6000-4 192GB显存 64核CPU 240GB内存, openbayes
- rtx-4090-4 96GB显存 80核CPU 320GB内存, openbayes
- a100 80GB显存 24核CPU 120GB内存, openbayes
- rtx-3090 24GB显存 24核CPU 30GB内存, openbayes
- rtx-3090-2 48GB显存 48核CPU 60GB内存, openbayes
- rtx-3090-4 96GB显存 96核CPU 120GB内存, openbayes
- rtx-4090-4 96GB显存 80核CPU 320GB内存, openbayes
测试方法
训练大致10min,去除第一行数据(略慢)计算平均训练速度
- v100: 1卡, batch_size 2/4
- a100: 1卡, batch_size 8/16/32
- 2080ti: 1卡, batch_size 2/4/8
- batch_size 8时 8min40s oom
- 3090: 1/2/4卡, batch_size 4/8
- 4090: 1/2/4卡, batch_size 4/8
- 4卡在batch_size 8时 9min30s oom
- a6000: 1/2/4卡, batch_size 4/8/16
accelerate配置文件样例
单卡
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: 'NO'
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
多卡
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
训练命令样例
accelerate launch src/train_bash.py --stage sft --do_train --model_name_or_path qwen/Qwen-1_8B --dataset belle_math --template default --finetuning_type lora --lora_target all --overwrite_cache --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16 --cache_dir cache --output_dir <output_dir> --per_device_train_batch_size <bs>
结果
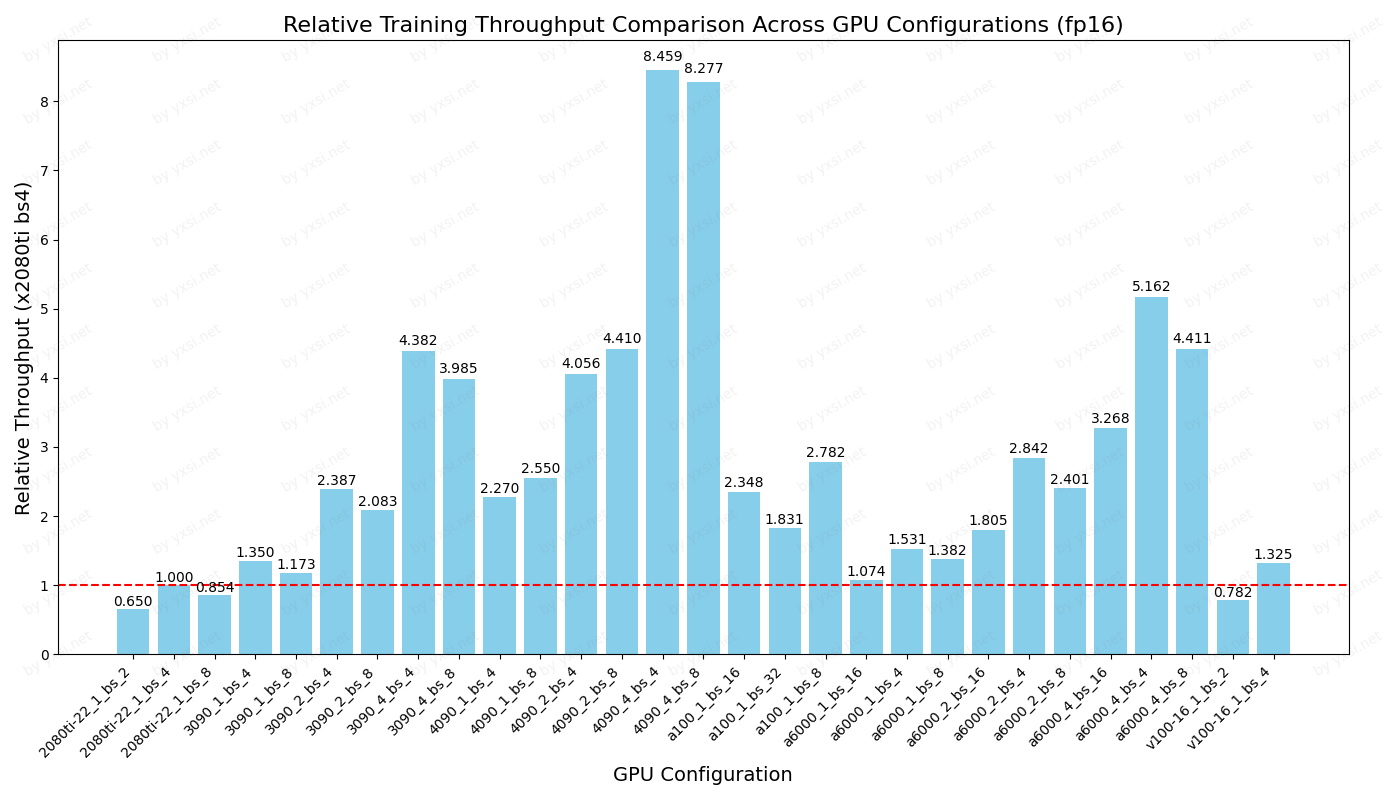
sample/s
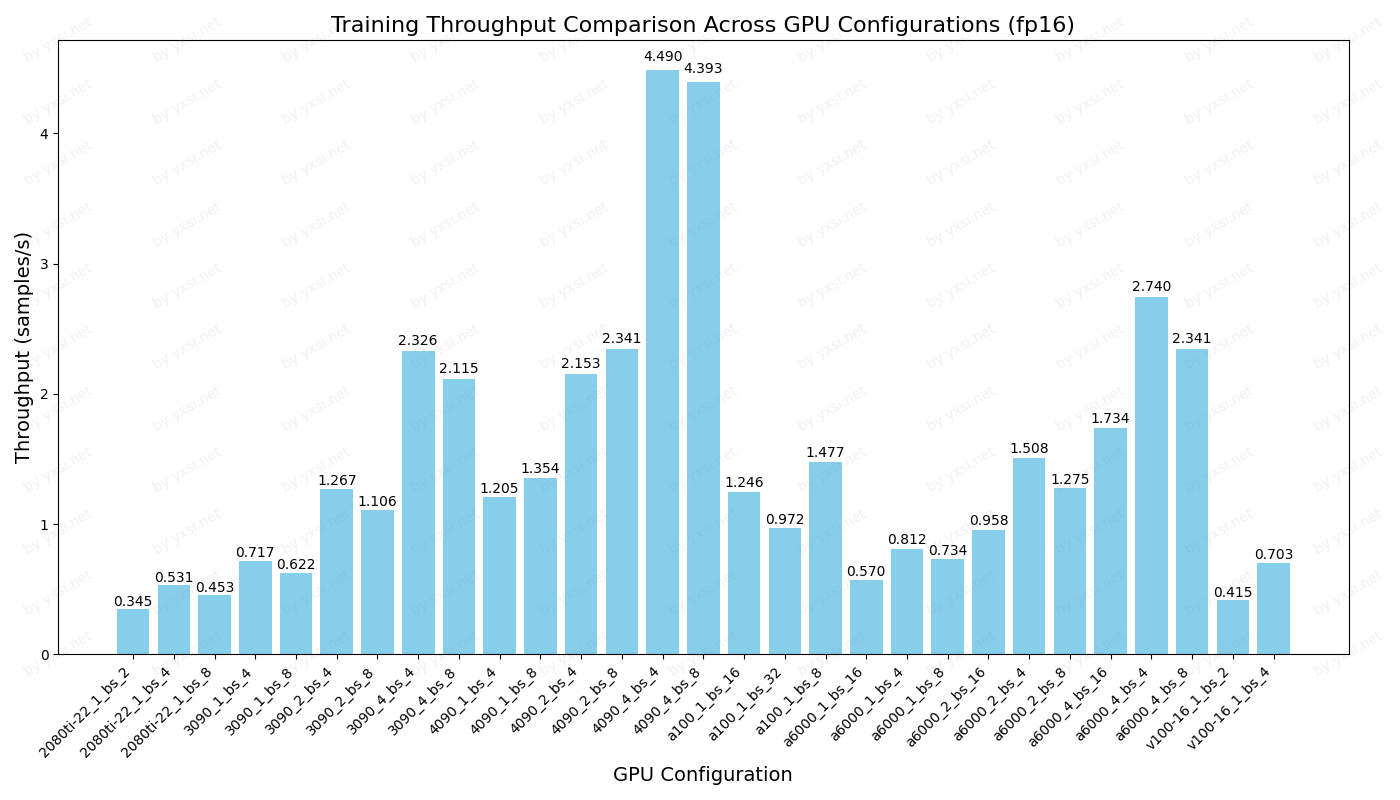
以2080ti bs4为基准的性能
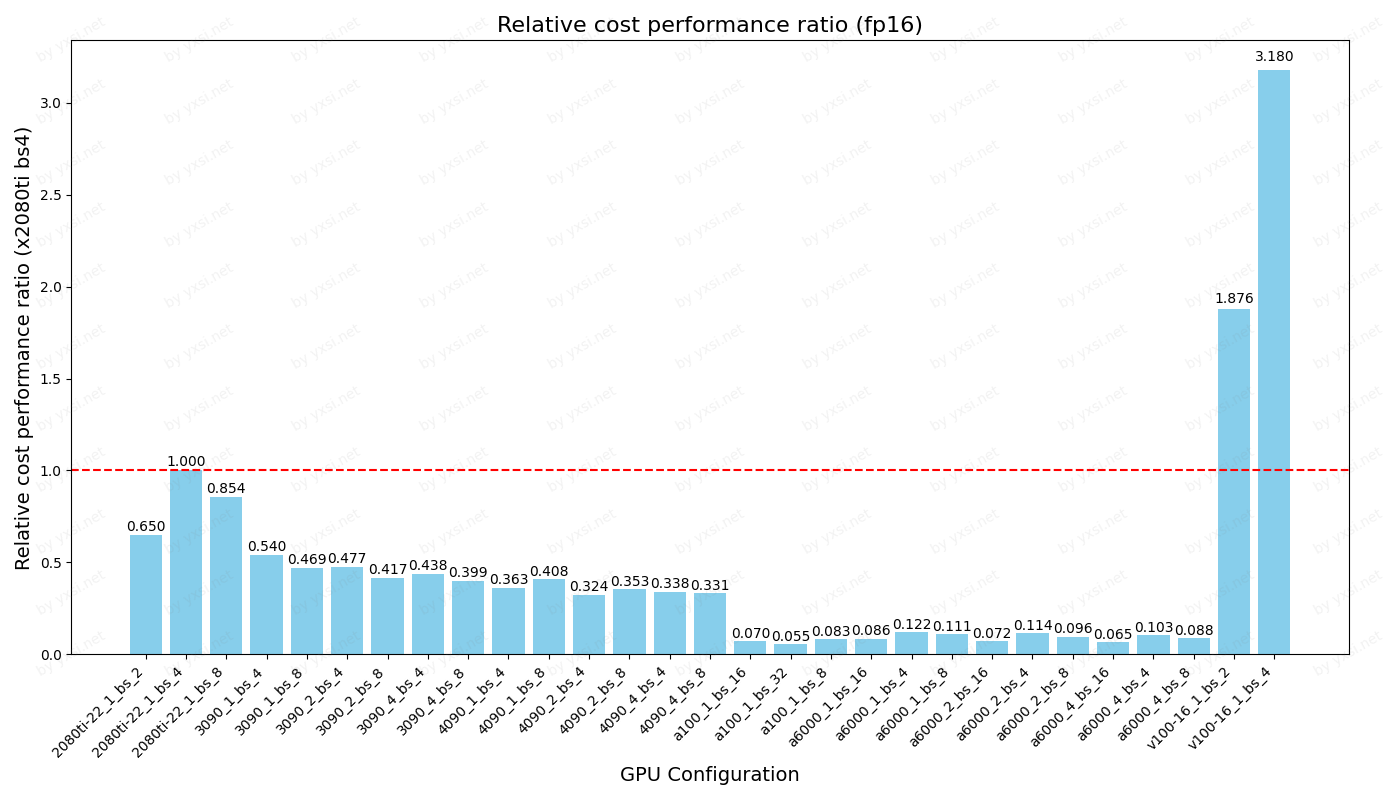
以2080ti bs4为基准的性价比
正常能买到的低价 主要来源为闲鱼
参考价格如下,时间为2024-02-24
| 卡 | 价格 |
|---|---|
| 4090 | 15000 |
| 3090 | 6000 |
| a100 | 80000 |
| 2080ti-改22G | 2400 |
| a6000 | 30000 |
| v100-16G | 1000 |